終於來到鐵人賽的最後一天~
即便是最後一天也不能鬆懈(?),今天的文章將會簡單摘要 Google 提出的文字生成影像模型 Imagen 有哪些值得注意的重點,最後再總結一下這一系列的文章
Imagen 的 paper:Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
和 DALL·E 2 一樣廢話不多說先放生成影像效果圖~

(圖片來源:Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding)
是不是感覺影像更天馬行空但又感覺很真實呢?Imagen 比 DALL·E 2 大約晚一個月提出,強調它能產生更高品質的影像且與文字條件更對應,而它與先前的模型有什麼不同呢?
先回顧一下 Imagen 的結構(如下圖),看起來和 DALL·E 2 一樣有處理文字條件的 text encoder、依據文字條件生成壓縮影像的 diffusion model 和兩個將影像解碼放大的 diffusion models,但事實上,Imagen 能產生高品質影像的關鍵就是 text encoder。
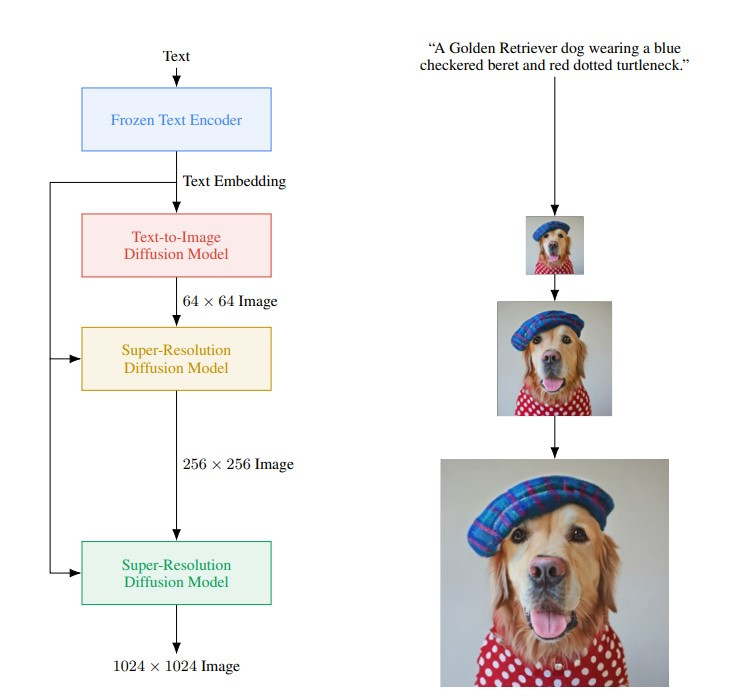
(圖片來源:Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding)
不同於 DALL·E 2 使用 CLIP 的技術,利用影像和文字成對資料同時訓練 image encoder 和 text encoder,Imagen 選擇用大量純文字預訓練好的大型語言模型 T5 作為 text encoder。由於純文字資料遠比文字和影像成對的資料更大量,這樣的 text encoder 有處理更廣泛的文字條件的能力,進而提升影像生成的品質以及和文字條件的對應程度。
除此之外,這個研究也發現 text encoder 越大(有越多參數),對於影像生成的品質以及影像和文字條件的對應程度都有明顯的幫助。下圖是他們的實驗結果,CLIP score 可以看成影像和文字的對應程度,而 FID 則可以視為生成影像和真實的差距,越低越好。
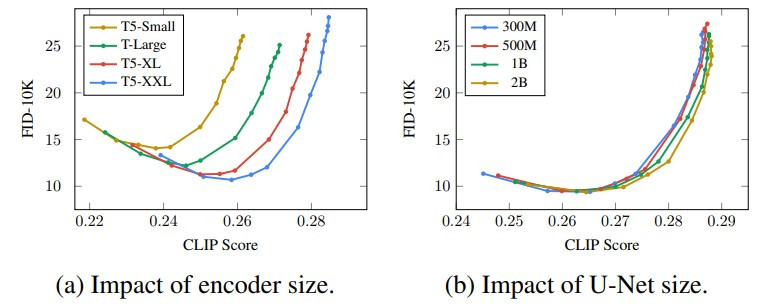
(圖片來源:Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding)
其中左邊的小圖呈現的是,當 text encoder T5 的大小越大(Small < Large < XL < XXL),不只影像看起來更逼真(FID 降低),影像和文字的對應性也更好(CLIP score 提高)。而右邊小圖則顯示,增加生成模型 diffusion model(U-Net 架構)的大小反而對生成影像品質影響不大。
之前在評估文字生成影像模型時,主要會以帶有說明文字的公開影像資料集 COCO(Common Objects in Context)作為基準,不過它的說明文字用來作為文字條件是有侷限性的,因此逐漸難以用來區分模型的優劣。
因此 Google 在這個研究中提出了新的評估基準 DrawBench,它提供更豐富也更具有挑戰性的文字條件(prompt),考驗模型是否能正確的在影像中呈現顏色、物品的數量、空間關係、場景中的文字等。
以下就是一些 DrawBench 中的 prompts,以及 Imagen 依據這些 prompts 產生的影像樣本:

(圖片來源:Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding)
回顧開始這一系列文章的初心,是希望自己能主動且持續的瞭解一個本來不太熟悉的領域,而跟 30 天前的自己比起來,我確實逐漸掌握了幾個經典的影像生成模型以及三個前沿的文字生成影像模型的基本概念,也玩了不少文字生成影像服務(希望大家也玩得開心
由於時間壓力緊迫,有時候資訊的輸入不免囫圇吞棗,偶爾會懷疑自己只是知識的搬運工 但寫出來的內容都是我有先確實理解過的,如果對於特定主題有更多的想法,我也會加入一些個人的觀點或解釋,希望讀過這系列文章的你們能得到一些與其他圖像生成科普/技術文有點不同的收穫~
但寫出來的內容都是我有先確實理解過的,如果對於特定主題有更多的想法,我也會加入一些個人的觀點或解釋,希望讀過這系列文章的你們能得到一些與其他圖像生成科普/技術文有點不同的收穫~
除此之外,我也有感參加鐵人賽的這段時間,是更瞭解自己的過程。雖然理想上要早早開始讀 paper 讀文章囤稿,規律的利用上班前和下班後的時間輸入與輸出,然實際上弄到每一天都在即興創作XD 瞭解自己或許就不是個很按部就班的人,讓自己順著動能前進,也意識到生活中有些事情是即使再怎麼忙碌也難以割捨...(白話:為了玩所以把寫文壓縮到通勤或其他零碎時間
這系列文章在撰寫的過程中就已經察覺到一些未竟之處,包括各式各樣 GAN 的變形、vector quantization 相關的方法、Stable Diffusion/DALL·E 2/Imagen 更多的技術細節,以及更多圖像生成 AI 的應用,多是因為內容編排的考量或時間的限制無法納入。圖像生成 AI 的研究如此繁多,我相信繼續探索下去一定會發現更多值得分享的內容,不過目前就先這樣啦~感謝大家的閱讀也感謝自己不完美的走完這段旅程


